Two-stage cluster sampling
Two-stage cluster
sampling
-
Rosma J Chackiath
INTRODUCTION
Often it is impossible or impractical to create a sampling frame of a target population, and/or the target population is widely dispersed geographically, making data collection costs relatively high. Such situations are ideal for cluster sampling.Cluster sampling is a probability sampling procedure in which the researcher divides the population into separate groups called clusters.
A two-stage cluster sample design includes all the steps in a single-stage cluster sample design with one exception, the last step. Let us consider a population where individuals are clustered into groups.To do a two-stage cluster sampling, in the first step, we will do one-stage cluster sampling, i.e., we are going to select a few clusters randomly from the population. Instead of selecting all elements from these selected clusters into our sample as we did in the one-stage cluster sampling, we randomly selected individuals within each cluster in our sample in two-stage cluster sampling. However, the number of individuals selected from each cluster does not have to be necessarily the same. The clusters which form the units of sampling at the first stage are called the first stage units, and the units or group of units within clusters which form the unit of clusters are called the second stage units or subunits.
EXAMPLE:
HOUSING DEVELOPMENT


1.Population divided into clusters 2. One stage cluster sampling

M is the cluster size,m is the sample size(selected clusters), ni is the no: of individuals selected from each cluster and Ni is the total number of individuals present in each cluster.


Two-stage sampling with equal first stage units
· Assume that the population consists of NM elements.
- NM elements are grouped into N first stage units of M second stage units each (i.e., N clusters, each cluster is of size M).
- Sample of n first stage units are selected (i.e., choose n clusters)
- Sample of m second stage units are selected from each selected first stage unit (i.e., choose m units from each cluster).
- Units at each stage are selected with SRSWOR at each stage are selected SRSWOR.
Important Formulas:
To calculate the average:
- First average the estimator over all the second stage selections that can be drawn from a fixed set of n units that the plan selects.
- Then
average over all the possible selections of n units by the plan





REAL-LIFE EXAMPLES:
This method can be used in health and social sciences. For instance, researchers used two-stage cluster sampling to generate a representative sample of the Iraqi population to conduct mortality surveys. Another real-life example is obtaining a sample of fishes from a commercial fishery Here, we take a sample of boats and then take a sample of fishes from each selected boat.
APPLICATIONS IN R
Example 1:
To illustrate the two-stage cluster sampling in R we are using the Swiss Municipalities Population in R.
About the dataset:
It is a data frame with 2896 observations on the following 22 variables. This population provides information about the Swiss municipalities in 2003.
Procedure and analysis:
Here the variable 'REG' (region) has 7 categories; it
is used as a clustering variable in the first-stage sample. The variable 'CT'
(canton) has 26 categories; it is used as a clustering variable in the
second-stage sample. 4 clusters (regions) are selected in the first-stage.1
canton is selected in the second-stage from each sampled region the method we
used here is simple random sampling without replacement in each stage(equal
probability, without replacement)



Interpretation:
Here we have selected 4 clusters (regions) in the first-stage and 1 canton is selected in the second-stage from each sampled region. We have used simple random sampling without replacement in each stage(equal probability, without replacement).
Example 2:
Here we are using two-stage sample from MU284
About the dataset:
The MU284 population comes from
Appendix B of the book "Model Assisted Survey Sampling" by Sarndal,
Swensson and Wretman, published by Springer-Verlag, New York, 1992. The data
set contains 284 observations on 11 variables, plus a line with variable names The
complete data are available from Statlib. Here our data is a two-stage sample
from the population, and it is a data frame with 15 observations and 5 variables.
Procedure and analysis:
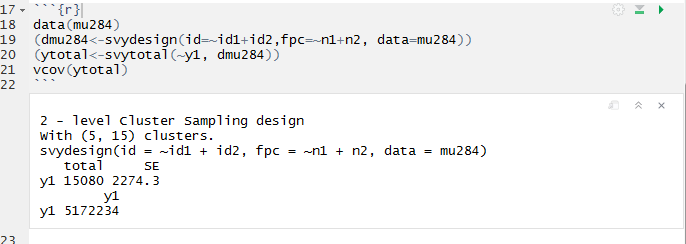
.Here, the argument id is given a “formula.” of variables that uniquely identify each primary sampling unit and the secondary sampling unit. The variables n1 and n2 indicate for each observation the number of clusters in the population.The summary verifies the number of sampled primary and sampling units and secondary sampling units, as well as the total number of primary sampling units in the population.
ADVANTAGES
The principle advantage of two-stage sampling is that it is more flexible than one-stage sampling. It reduces to one stage sampling when m=M, but unless this is the best choice of m, we have the opportunity of taking some smaller value that appears to appear more efficient. As usual, this choice reduces to a balance between statistical precision and cost. When units of the first stage agree very closely, then consideration of precision suggests a small value of m. On the other hand, it is sometimes as cheap to measure the whole of a unit as to a sample. For example, when the unit is a household and a single respondent can give as accurate data as all household members.


Comments
Post a Comment